How big is a JavaScript string?
The many sizes of a JS string

When measuring a string in JavaScript, string.length comes to mind. However, that property does not tell the full story. Strings have many sizes: code units, code points, bytes, pixels, terminal columns.
Let’s dive into their differences.
Code units
Each string element in JavaScript is a UTF-16 code unit. In other words, any string[index], commonly (and ambiguously) referred to as a string “character.”
Code units are fast and convenient to use since they underpin all string operations (with a few exceptions noted below) including string.length, string.slice(), string === string, string.replace() and so on.
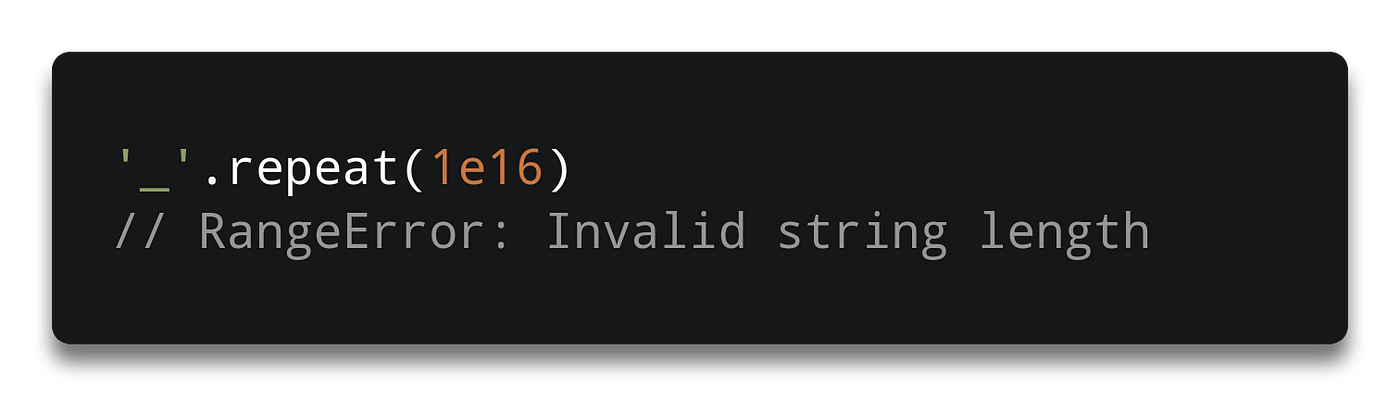
Strings have a maximum size in code units. While the standard defines it as at most ~9e15, JavaScript engines implement much lower limits: ~5e8 with V8, ~1e9 with SpiderMonkey and ~2e9 with JavaScriptCore.
Code points
A Unicode code point is a number identifying a single abstract character. It is often noted in hexadecimal: for example, the decimal number 129445 would be written U+01F9A5 🦥 (sloth). Unicode maintains a list of characters with code points ranging:
- From
U+000000toU+00007F: ASCII - From
U+000080toU+00FFFF: BMP (Basic Multilingual Plane) - From
U+010000toU+10FFFF: Astral code points. This is where you’ll find emoji! 🎶
Usually, a UTF-16 code unit is equivalent to a code point. For example, "Olá!" has 4 code units with their own code points: U+004F, U+006C, U+00E1 and U+0021.

However, astral code points (U+010000 and above) are broken down into two code units:
- First, a “high/leading surrogate” from
\uD800to\uDBFF - Then, a “low/trailing surrogate” from
\uDC00to\uDFFF
For example, U+01F9A5 becomes \uD83E and \uDDA5. This conversion from a code point to a surrogate pair is specific to UTF-16. If you’re curious about it, please check this code sample.

This only applies if the two surrogates follow each other in that order. In JavaScript, isolated or inverted surrogates are valid but considered their own code points and generally either invisible or printed as � (replacement character U+FFFD).
Since most string operations use code units, surrogates can be a problem. In some cases, they work just fine. For example, the following statements are correct because "🦥" is equivalent to "\uD83E\uDDA5", i.e. to the full surrogates pair.
![`const string = “🦥” \n string === “🦥” // true \n /🦥/.test(string) // true \n string + “🐨” // “🦥🐨” \n string.replace(“🦥”, “🐨”) // “🐨” \n “🐨🦥🐨”.split(“🦥”) // [“🐨”, “🐨”]`](https://miro.medium.com/v2/resize:fit:1400/1*Ep4BYddRb0V6RlGZ2X4Xnw.png)
However, some string operations might target individual surrogates and split the pair.
![`const string = “🦥” \n string[0] // “\uD83E” \n string[1] // “\uDDA5” \n string[0] === “🦥” // false \n /^.$/.test(string) // false \n /^..$/.test(string) // true \n string.length // 2 \n “🦥🐨🐨”.slice(2) // “🐨🐨” \n string.replace(/./g, “🐨”) // “🐨🐨” \n […string.matchAll(/./g)] // [[“\uD83E”], // [“\uDDA5”]]`](https://miro.medium.com/v2/resize:fit:1400/1*acPYf6svc_yKT1rZ7-ZmJA.png)
Fortunately, a few string operations use code points instead of code units:
- Iterations, including
[...string]andfor (const codepoint of string), but excludingfor (const index in string) - Regular expressions with the Unicode flag:
/.../u \u{000000}instead of\u0000string.codePointAt()andString.fromCodePoint()instead ofstring.charCodeAt()andString.fromCharCode()string.to*Case()andstring.trim*()
![`const string = “🦥” \n string === “\uD83E\uDDA5” // true \n string === “\u{01F9A5}” // true \n /^.$/u.test(string) // true \n […string].length // 1 (code points) \n […”🦥🐨🐨”].slice(2).join(“”) // “🐨” (slice/truncate by code point) \n string.replace(/./gu, “🐨”) // “🐨” \n […string.matchAll(/./gu)] // [[“🦥”]] \n string.charCodeAt(0) // 0xD83E \n string.charCodeAt(1) // 0xDDA5 \n string.codePointAt(0) // 0x1F9A5 \n string.codePointAt(1) // 0xDDA5. Careful: the return value of `codePoint`](https://miro.medium.com/v2/resize:fit:700/1*usQYO_N0SaodVAS4kTqtVQ.png)
Bytes
When a string is written to a file or sent over the network, it is first serialized to a series of bytes. This binary representation differs from code units and code points.
Character encodings translate each code point into one or several bytes. While there are quite many of them, the most common ones these days are UTF-16 and UTF-8.
Since JavaScript strings are based on UTF-16, their binary representation in that character encoding is straightforward (aside from endianness): each code unit translates to an equivalent bytes pair.

For UTF-8, each code point translates to a series of 1 to 4 bytes. Lower Unicode code points take fewer bytes. In particular, ASCII characters are 1 byte long. On the other hand, astral code points are 4 bytes long. The conversion logic is explained in details here.

Some JavaScript packages are available for common operations like retrieving a string’s size in bytes or slicing it bytewise (see string-byte-length and string-byte-slice). Otherwise, Uint8Arrays can be used to represent series of bytes and TextEncoder/TextDecoder to convert strings to/from them.
![`const encoder = new TextEncoder() \n const decoder = new TextDecoder() \n const string = “🦥” \n const uint8Array = encoder.encode(string) // [0xf0, 0x9f, 0xa6, 0xa5] (UTF-8 bytes) \n decoder.decode(uint8Array) // “🦥”`](https://miro.medium.com/v2/resize:fit:700/1*dL4ZpoejppukDNcx1eRw1A.png)
Buffers are a Node.js alternative with a few additional features.
![`const string = “🦥” \n const buffer = Buffer.from(string) // [0xF0, 0x9F, 0xA6, 0xA5] \n buffer.toString() // “🦥”`](https://miro.medium.com/v2/resize:fit:700/1*h8zfyliwruOd4pZuU_NFsA.png)
Width
When displayed, a string occupies a platform-specific width. For example, browsers use pixels, em, etc. We’ll focus on terminals, which use columns.
Terminals print characters in a grid pattern. Computing a string’s width primarily helps with vertical alignment and padding. Also, while terminals do wrap lines automatically, manual wrapping can be needed for similar reasons.
Determining a string’s terminal width is rather intricate.
To begin with, considering some terminals or fonts might not handle exotic characters well, cross-platform terminal characters should be preferred for consistent behavior.

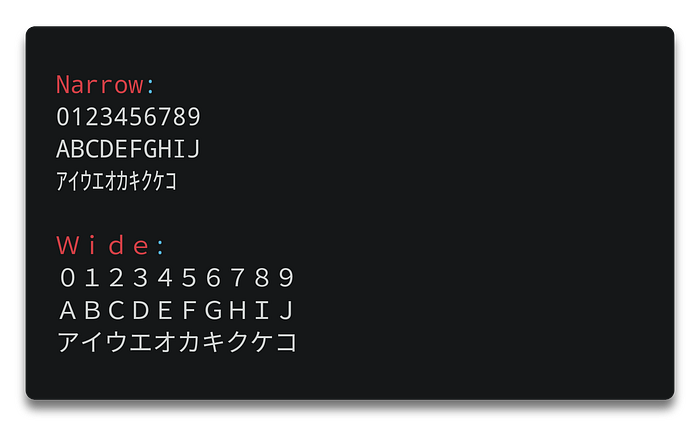
Also, while most code points are 1 column wide, fullwidth characters are 2 columns wide. Those usually represent Chinese, Japanese and Korean logograms. Common code points such as ASCII characters are sometimes available as wide or narrow variants. Unicode provides a list with each code point’s width, which can be accessed through some helper modules.
Furthermore, some code points are meant to be combined with another. Those are usually accents and other diacritics. For example, a (U+0061) followed by a combining grave accent (U+0300) is displayed like à (U+00E0) which is 1 column wide. string.normalize() composes/decomposes those.
Other examples include variation selectors: # (U+0023) succeeded by the emoji variation (U+FE0F) produces a hashtag emoji#️. Or flags: 🇪 (U+1F1EA) and 🇺 (U+1F1FA) result in the EU flag 🇪🇺.
Emoji modifiers behave similarly. For instance, 👩 (woman, U+1F469) followed by medium skin tone (U+1F3FD), zero-width joiner (U+200D) and 🔬(microscope, U+1F52C) is shown as 👩🏽🔬 (woman scientist, medium skin tone), 2 columns wide.

A few code points are even invisible. Among many purposes (even music notation! 🎷), those are intended to join or separate characters, symbols or words (zero-width space U+200B, word joiner U+2060) and set text direction (left-to-right mark U+200E, right-to-left mark U+200F).
Finally, control characters don’t have any width because they are not meant to be printed. Instead, they modify terminal parameters such as cursor position, scrolling, character set, communication, message structure, etc. One of them even emits sounds 🎤. They are divided into several categories:
- C0 control characters (
U+0000toU+001F) which are part of ASCII. Those are the oldest ones, with some dating back to 1870 🚂! They include line feed, null and backspace. Some of them can be represented using backslash sequences such as\n,\0or\b. - C1 control characters (
U+0080toU+009F) which are rarely used. - Other code points such as language tags.
- ANSI escape sequences. Those do not have any Unicode code points. They are represented using sequences that start with
\e. The most common ones change colors, e.g.\e[31msets the font’s color to red. But many more are available. Several modules simplify detecting or stripping them.
With everything considered, manipulating a string’s width in terminals might seem daunting. Fortunately, a few packages help with computing it or slicing/truncating a string to fit a specific amount of columns.
In most cases, the difference between the above units is straightforward. Choosing the right one can prevent some bugs, such as computing a string’s terminal width using string.length or matching an emoji string with a RegExp lacking the u flag.
That being said, their performance cost might vary. For example, converting a large string to/from binary can be slow. Also, JavaScript operations using code units tend to run slightly faster than the code points ones. This can lead to preferring a less accurate unit inside critical hot paths.
In a nutshell, each unit presents the same information to different targets: machines (bytes), developers at an implementation (code units) or abstract level (code points), and users (width).
Go composable: Build apps faster like Lego

Bit is an open-source tool for building apps in a modular and collaborative way. Go composable to ship faster, more consistently, and easily scale.
Build apps, pages, user-experiences and UIs as standalone components. Use them to compose new apps and experiences faster. Bring any framework and tool into your workflow. Share, reuse, and collaborate to build together.
Help your team with:

